You think that putting the disallow rules into your robots.txt will stop your site showing up in the search engines. So you place the following into your robots.txt file to block web crawlers:


This should block all robots from crawling right? … err right. And then you discover at a later stage your pages are somehow still showing up in Google or Bing. Not good, you were not ready with your new site design yet, and now it’s listed in the Search engines. What’s going on here?

There are a few concepts to understand, and the first is the difference between being listed in the search engine results and that of actually being indexed. Since we often think that we need our site to be indexed before it will block web crawlers, and not show up in the search results right? Well not exactly.
Nishanth Stephen Google can still decide to crawl and eventually index the site based on external information such as incoming links, that it is relevant.
Remember there are many ways for URLs to be discovered and crawled on the internet. Including of course one of the most obvious which is discovery via links pointing to your URL. So even if the robots.txt file has told those robot spiders to obey the Disallow you put in the file, your URL can still be indexed. Google makes this point very clear, read more here: http://support.google.com/webmasters/bin/answer.py?hl=en&answer=156449
Matt Cutts explains Uncrawled URLs in search results
If there are follow links pointing to your URL, then Google follows those links. So the URL still appears in search results. So it might show up in your Search results, depending what search you did, but it might not actually be indexed. Here is a great guide from Joost de Valk, to help you make sure your URLs do not get indexed.
Infographic quick tips how to block web crawlers
.
Disallow in robots.txt to block crawlers
What actually happens when we use the robots.txt file to block robots. As you can see in this image, it is telling you why a description is not available. The website url is still discovered but it does not show the description.
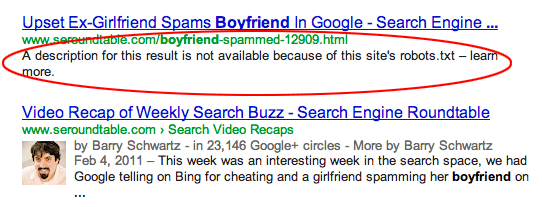
Barry Schwartz reported on a descriptive search snippet for when blocked by the robots.txt file. Google started showing these descriptive search snippets for when it cannot show a desciptive result, back in 2012.
It’s commonly misunderstood that using this approach will stop your site from getting into the search results. However since you are actually blocking the crawler from accessing the URL, it just means it cannot describe what’s on that page.
Sha Menz In a nutshell – Locking the front door does not stop people climbing in an open window 🙂
My favorite post of all-time was written by Lindsay Wassell a very long time ago, but still holds true https://moz.com/blog/restricting-robot-access-for-improved-seo
**Be careful not to use nofollow without careful thought
It’s also known that page on your site get indexed when your page is shared, and as mentioned by Tony below by G+ buttons
Tony McCreath I recall at some point Google stated that they would override these requests if other signals contradicted. It was the presence of a G+ button. Other things like canonicalisation can also confuse things.
Robots.txt disallows access to a URL, it does not stop it being added to the search index. It just stops its content being used. The noindex meta tag let’s a page get crawled and technically it is indexed, but it is not to be shown in search results. Nofollow is a different thing.
A more reliable way of making sure your URL does not appear in the search results is by using the meta robots noindex tag.
Meta robots tag to stop URL listing
To make sure your pages don’t appear the search engines you will need to think carefully about indexing them. So prevent listing your URL in the search results is to use the meta robots tag. Like this:
![]()
I’ll use the below tag to allow search engines to follow and pass link equity, but noindex the pages:
![]()
John S. Britsios The only difference between robots.txt and meta noindex,nofollow is, that with robots the bots cannot access the page at all and with the meta they can access the page but cannot pass equity through the links of the page. And the second option creates dangling pages (nodes). If you use the meta directives, you should use noindex,follow. Then you will have things right.
If you do not have any meta robots tag specified on your site, then it will default to index, follow. Which is essentially the same as specifiying this tag:
![]()
More info can be found in detail. Danny Sullivan’s Guide: Meta Robots Tag 101
Danny said: The meta robots tag was an open standard created over a decade ago and designed initially to allow page authors to prevent page indexing. Over the years, various search engines have added additional support to the tag.
The X-Robots-Tag HTTP header
Another easier way to implement this at a sitewide level is to use the X-Robots-Tag HTTP header. You add this to your .htaccess file:
![]()
This works for Apache servers with mod_headers enabled. Once this line is added, it will work for the entire site.
Again, what this means is the site is effectively indexed, but does not appear in the search results.
Password protect to block web crawlers
If you really want to block web crawlers from accessing and indexing your site and showing up in the results in the search results, password protect your site. It’s quite easy to implement a .htaccess password so that no crawler can proceed. This will make sure that nothing that is password protected will be crawled, and never make it into the index.
Dawn Anderson XML sitemaps and other internal links. Links to testing sites seem to be areas where you see this a lot. Best to block testing sites with either password login or IP inclusion lists defined in config files. Of course, if dynamic IPs are in the mix it gets a bit more problematic
More related crawling and indexing resources
Understanding robots and crawlers, and many of the finer details of how these crawl theory works, can give you an advantage as an SEO. Here are some links to great resources to learn more:
- Google’s Robots meta tag and X-Robots-Tag HTTP header specifications
- Crawl Efficiencey on SEMrush by Dawn Aderson
- Google Webmasters hangouts

Peter Mead shares over 20 years experience in Digital and as an expert SEO Consultant. Peter draws further knowledge and experience from his involvement as a SEMrush Webinar host and a co-organizer of Melbourne SEO Meetup. Writing articles based on his hands-on analytical and strategic experience. Peter is passionate about contributing to client success and the improvement of the broader SEO community.
Peter can be found on some of these sites:
Hosting the SEMrush Australian Search Marketing Academy Webinar: https://www.semrush.com/user/145846945/
WordPress SEO Consultant: Peter Mead iT https://petermead.com/
Co-Organiser: Melbourne SEO Meetup https://www.meetup.com/Melbourne-SEO/
More information About Peter Mead